Dictionnaires⚓︎

Préambule : retour sur le cours de Première.
0. Notion de tableau associatif⚓︎
Un tableau associatif est un type abstrait de données (au même titre que les listes, piles, files, vues précédemment). Ce type abstrait de données a la particularité de ne pas être totalement linéaire (ou «plat») puisqu'il associe des valeurs à des clés.
Il est habituellement muni des opérations suivantes :
- ajout d'une nouvelle valeur associée à une nouvelle clé (on parlera de nouveau couple clé-valeur)
- modification d'une valeur associée à une clé existante
- suppression d'un couple clé-valeur
- récupération de la valeur associée à une clé donnée.
Un répertoire téléphonique est un exemple de tableau associatif :
- les clés sont les noms
- les valeurs sont les numéros de téléphone
En Python, le dictionnaire est une structure native de tableau associatif.
1. Dictionnaire et temps d'accès aux données⚓︎
1.1 Protocole de mesure⚓︎
Le but est de créer une liste et un dictionnaire de même taille (arbitraire), et de comparer ensuite le temps de recherche d'un élément n'appartenant pas à ces deux structures.
Q1. Créer une fonction fabrique_liste qui prend en paramètre un entier nb et qui renvoie une liste composée de tous les entiers de 0 à nb-1.
Correction
def fabrique_liste(nb):
lst = [k for k in range(nb)]
return lst
Q2. Créer une fonction fabrique_dict qui prend en paramètre un entier nb et qui renvoie dictionnaire composé de paires qui associent à toutes les clés k de 0 à nb-1 leur propre valeur k.
Correction
def fabrique_dict(nb):
dct = {k:k for k in range(nb)}
return dct
Q3. Créer une fonction mesures qui prend en paramètre un entier nb et qui :
- Créé une liste et un dictionnaire de taille
nbà l'aide des fonctions précédentes. - Mesure la recherche d'une valeur inexistante dans la liste, et affiche le temps de recherche.
- Mesure la recherche d'une valeur inexistante dans le dictionnaire, et affiche le temps de recherche.
Cette recherche d'une valeur inexistante s'appelle recherche dans le pire des cas.
Comment faire la recherche ?
Il est impératif d'utiliser le mot-clé in propre à Python afin de bénéficier des avantages (ou inconvénients) de chacune des deux structures.
Si on cherche notre élément en parcourant «à la main» la totalité de la structure, on aura forcément un temps de recherche proportionnel au nombre d'éléments de la structure (et donc une complexité linéaire).
En utilisant le mot-clé in, on va laisser Python gérer tout seul la recherche.
Pour davantage de précision, on pourra dans un second temps effectuer plusieurs mesures et faire une moyenne des temps obtenus.
Pour rappel, l'import du module time permet d'appeler la fonction time.time().
Correction
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | |
Q4. Effectuer des mesures avec différentes valeurs de nb.
1.2 Mesures⚓︎
Nous allons effectuer 3 mesures, avec une taille de liste et de dictionnaire augmentant d'un facteur 10 à chaque fois.
>>> mesures(10**4)
temps pour une liste de taille 10000 : 0.00023534297943115235
temps pour un dictionnaire de taille 10000 : 1.6689300537109374e-07
>>> mesures(10**5)
temps pour une liste de taille 100000 : 0.0012505292892456056
temps pour un dictionnaire de taille 100000 : 4.5299530029296873e-07
>>> mesures(10**6)
temps pour une liste de taille 1000000 : 0.012522673606872559
temps pour un dictionnaire de taille 1000000 : 2.384185791015625e-07
- la recherche dans une liste prend un ordre de grandeur à chaque fois : elle est environ 10 fois plus grande quand la taille de la liste est 10 fois plus grande.
- la recherche dans le dictionnaire reste dans le même ordre de grandeur (\(10^{-7}\) secondes).
On remarque donc que le temps moyen de recherche dans un dictionnaire est remarquablement constant.
Il ne dépend pas du nombre d'éléments du dictionnaire dans lequel on cherche. On dit qu'il est en \(O(1)\).
1.3 Conclusion⚓︎
Temps de recherche 
Il y a donc une différence fondamentale à connaître entre les temps de recherche d'un élément à l'intérieur :
- d'une liste : temps proportionnel à la taille de la liste (ordre de complexité linéaire, \(O(n)\))
- d'un dictionnaire : temps constant, indépendant de la taille du dictionnaire (ordre de complexité constant, \(O(1)\))
Attention : en ce qui concerne les temps d'accès à un élément, la structure de tableau dynamique des listes de Python fait que ce temps d'accès est aussi en temps constant (comme pour les dictionnaires). On voit alors que les listes Python ne sont pas des listes chaînées, où le temps d'accès à un élément est directement proportionnel à la position de cet élément dans la liste.
1.4 One more thing...⚓︎
Intéressons-nous maintenant à ce qui semble être un peu trop miraculeux : une recherche en temps constant, quelque soit la taille du dictionnaire ? Mesurons cette fois non pas la recherche dans le dictionnaire, mais la création de celui-ci :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
>>> mesures(10**5)
temps pour liste de taille 100000 : 0.004771041870117188
temps pour un dictionnaire de taille 100000 : 0.012260651588439942
>>> mesures(10**6)
temps pour liste de taille 1000000 : 0.04549875259399414
temps pour un dictionnaire de taille 1000000 : 0.14215753078460694
>>> mesures(10**7)
temps pour liste de taille 10000000 : 0.4727184295654297
temps pour un dictionnaire de taille 10000000 : 1.302360200881958
La création des deux structures semble de complexité linéaire, mais elle est surtout bien plus grande pour un dictionnaire que pour une liste... Pourquoi ?
Parce que pour bénéficier plus tard d'une recherche en temps constant, la création du dictionnaire demande beaucoup de calculs...
Petit détour par les fonctions de hachage :
2. Fonctions de hachage (hors-programme)⚓︎
Tout ce qui suit est hors-programme de Terminale, mais permet de comprendre comment Python arrive à faire de la recherche en temps constant quelle que soit la taille du dictionnaire.
Il est important de se rappeler qu'un dictionnaire n'est pas ordonné (contrairement à l'objet «dictionnaire» de la vie courante, où chaque mot est classé suivant l'ordre alphabétique).
On n'accède pas à une valeur suivant sa position, mais suivant sa clé.
Dans une liste, lorsqu'on veut savoir si un élément appartient à une liste (problème de la recherche d'élément), il n'y a pas (dans le cas général) de meilleure méthode que le parcours exhaustif de tous les éléments de la liste jusqu'à (éventuellement) trouver la valeur cherchée.
Dans un dictionnaire, on pourrait s'imaginer qu'il va falloir parcourir toutes les clés et regarder les valeurs correspondantes. Il n'en est rien.
Pour comprendre cela nous allons faire un petit détour par les fonctions de hachage.
2.1 Vérification de l'intégrité⚓︎
Lorsque vous téléchargez un fichier important et que vous souhaitez vérifier qu'il n'a pas été corrompu lors du téléchargement (ou avant), vous avez parfois la possibilité de vérifier l'intégrité de votre fichier téléchargé, en calculant une «empreinte» de votre fichier et en la comparant avec celle que vous êtes censée obtenir :
Voilà par exemple ce qui apparaît sur la page de téléchargement d'une iso d'ubuntu 18.04 :

La clé MD5 proposée pour chaque fichier est le résultat ce que doit donner le fichier (ici une iso d'environ 1,9 Go) lorsqu'il est «haché» par la fonction MD5. Dans notre cas, si nous téléchargeons
ubuntu-18.04.3-desktop-amd64.iso, nous devons calculer l'empreinte du fichier téléchargé et vérifier que nous obtenons bien 72491db7ef6f3cd4b085b9fe1f232345 :
Essayons :

La clé calculée sur l'ordinateur correspond bien à celle indiquée sur le site de téléchargement : le fichier est intègre.
Exemple
Téléchargez le fichier banniere.png et dans un Terminal, calculez son empreinte MD5 :
{kind=link}
eleve@linux:~/ md5sum banniere.png
2895bae45eb0ab36a2a8324c0208ad95 banniere.png
Si votre fichier banniere.png a été convenablement téléchargé, votre empreinte devra être égale à 2895bae45eb0ab36a2a8324c0208ad95.
2.2 Mécanisme de la fonction de hachage⚓︎
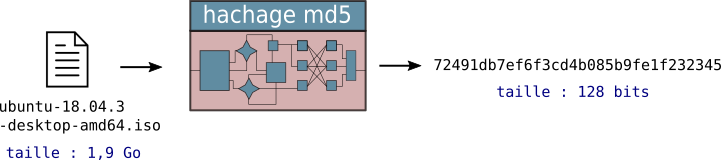
Quelle que soit la taille du fichier donné en entrée, la fonction MD5 va le réduire à un mot de 128 bits. Ce mot binaire de 128 bits est représenté par une chaîne de 32 caractères (en hexadécimal, de 0 à f). Il y a donc \(2^{128}\) (de l'ordre de \(10^{39}\)) empreintes MD5 différentes, ce qui rend quasiment impossible le fait d'avoir un mauvais fichier qui donnerait (par un très très mauvais hasard) la bonne empreinte.
Le mécanisme effectif de calcul de la fonction MD5 est très complexe : une explication en est donnée ici.
Il est évidemment impossible de revenir en arrière et de recréer le fichier original à partir de l'empreinte MD5. Dans le cas contraire, cela voudrait dire qu'on est capable de compresser sans perte un fichier de 1,9 Go en une chaîne de 128 bits. Cette impossibilité de trouver une fonction réciproque à la fonction de hachage est très importante en cryptographie.
En effet, les simples chaînes de caractères peuvent aussi être transformées par une fonction de hachage :


(on pourra aussi jouer avec le fabuleux site https://gchq.github.io/CyberChef du GHCQ)
Quel est l'intérêt de hacher une chaîne de caractère ? La conservation des mots de passe !!!
2.3 Le stockage des mots de passe⚓︎
Les sites qui nécessitent une authentification par login / mot de passe ne conservent pas en clair les mots de passe sur leur serveur. La moindre compromission de leur serveur serait en effet dramatique. Ce qui est conservé est l'empreinte du mot de passe après son passage par une fonction de hachage.
Par exemple, un site où notre mot de passe serait vive la NSI conserverait dans ses bases de données l'empreinte e74fb2f94c052bbf16cea4a795145e35.
À chaque saisie du mot de passe côté client, l'empreinte est recalculée (côté serveur), puis comparée avec l'empreinte stockée.
Lors du transit du mot de passe, le chiffrement effectué par le protocole https assure la protection en cas d'interception.
De cette façon, si le serveur est compromis, la non-réversibilité de la fonction de hachage assure que le mot de passe ne peut pas être retrouvé par les attaquants.
2.4 La non-réversibilité de la fonction de hachage (vraiment ?)⚓︎
Prenons notre empreinte MD5 e74fb2f94c052bbf16cea4a795145e35 et allons fureter du côté de (par exemple) https://md5.gromweb.com/
Notre empreinte ne résiste pas bien longtemps...
Calculez l'empreinte de FrançoisMauriacFTW et demandez au site de tenter de l'inverser. Que constatez-vous ?
Les empreintes des mots de passe les plus fréquents sont stockées dans des tables (qu'on appelle rainbow tables ou tables arc-en-ciel) qui rendent possibles le déchiffrage de ces empreintes.
Pour contrer cela, les cryptographes rajoutent des caractères avant hachage (le sel), et choisissent surtout des bonnes fonctions de hachage. MD5 et SHA-1 ne sont plus utilisées, on préfère maintenant SHA-256 (voir ici).
3. Retour aux dictionnaires⚓︎
Quel est le lien entre les fonctions de hachage et les dictionnaires ???
L'idée essentielle est que chaque clé est hachée pour donner une empreinte unique, qui est ensuite transformée en un indice de positionnement dans un tableau.
Le dictionnaire :
d = {"pommes":3, "poires":0, "bananes":5}
serait donc par exemple implémenté dans un tableau comme celui-ci :
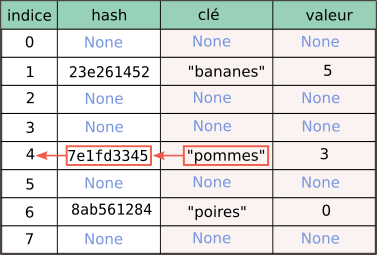
On peut remarquer que ce tableau laisse beaucoup de cases vides.
Si je souhaite ensuite accéder à l'élément d["kiwis"] :
- le hash de la chaîne
"kiwis"est calculé. Par exemple,4512d2202. - l'indice de la position (éventuelle) de la clé
"kiwis"dans mon dictionnaire est calculé à partir de ce hash4512d2202. Dans notre exemple, cela pourrait donner l'indice 3. - Python accède directement à cet indice du tableau :
- si la valeur de la clé sur cette ligne du tableau est None, cela signifie que
"kiwis"n'est pas une clé existante du tableau. C'est notre cas ici car il n'y a rien à la ligne 3. - si la valeur de la clé sur cette ligne du tableau est bien
"kiwis", la valeur correspondante est renvoyée.
- si la valeur de la clé sur cette ligne du tableau est None, cela signifie que
En résumé, Python sait toujours où aller chercher un élément de son dictionnaire : soit il le trouve à l'endroit calculé, soit il n'y a rien à cet endroit calculé, ce qui veut dire que l'élément ne fait pas partie du dictionnaire.
Par ce mécanisme, l'accès à un élément du dictionnaire se fait toujours en temps constant.
Il existe une manière de «voir» que Python utilise une fonction de hachage pour implémenter un dictionnaire :
mondico = {}
# un nombre peut-il être une clé?
mondico[4] = "foo"
# une chaîne de caractères peut-elle être une clé ?
mondico["riri"] = "fifi"
# une liste peut-elle être une clé ?
mondico[[2,5]] = "loulou"
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-1-585560b5c422> in <module>
8
9 # une liste peut-elle être une clé ?
- 10 mondico[[2,5]] = "loulou"
TypeError: unhashable type: 'list'
Le message d'erreur est explicite : le type list que nous avons voulu utiliser comme clé n'est pas hachable, car c'est un type d'objet pouvant être modifié a posteriori tout en gardant la même référence (on dit que c'est un objet mutable):
a = [3, 6, 8]
print(id(a))
a.append(12)
print(id(a))
139646950377032
139646950377032
Ce changement de valeur tout en gardant la même référence détruirait le principe associant à une clé unique une position unique dans le tableau implémentant le dictionnaire.
Ce problème ne se pose pas si la variable désigne une chaîne de caractères, ou un nombre :
a = 2020
print(id(a))
a += 1
print(id(a))
139646916523440
139646916523504
Un variable contenant un entier est donc un objet immuable car si on modifie la valeur de l'entier, la référence de la variable changera aussi. Comme un dictionnaire a besoin d'avoir des clés dont les références soient définitives, seuls les objets immuables peuvent donc servir de clés dans les dictionnaires.